Model2Vec: Distill a Small Fast Model from any Sentence Transformer
(Large) language models have become the de facto standard for feature extraction. While these models have shown state-of-the-art performance on a large number of tasks they also come with heavy resource requirements: large energy consumption, computational demands, and longer processing times. Although there are many ways in which you can make existing (Sentence) Transformers faster, e.g. quantization, or specialized kernels, they are still relatively slow, especially on CPU. What if you need to go faster and are working on a time-constrained product (e.g. a search engine), or have very little resources available? This is where Model2Vec comes in — offering static embeddings that are hardware and eco-friendly while maintaining strong performance. In this blog, we will discuss what Model2Vec is, how it works, how you can use it, and its performance. |
|---|
| Visualization of the Model2Vec architecture. |
Table of Contents
What is Model2Vec?
Model2Vec is a technique to distill a small, fast, high performance static model from any Sentence Transformer. At a high level, it works by passing a vocabulary through a sentence transformer model, then reducing the dimensionality of the resulting embeddings using PCA, and finally weighting the embeddings using zipf weighting. No dataset is needed, just a model (and optionally, a vocabulary). During inference, we simply take the mean of all token embeddings occurring in a sentence. A Model2Vec model is therefore completely uncontextualized. While this may sound like a big downside, we’ll show that it still performs quite well considering how small and fast it is. The above might sound like a lot to you, so let’s unpack this a little.Transformers and embeddings
In a sentence transformer encoding step, a string is first chopped up into subword tokens. The embeddings of these tokens are then fed through the model, which contextualizes them to create high-quality sentence representations. At the output, you get as many embeddings as you put in, so if your input sentence consists of 10 tokens, you also get 10 output tokens. These tokens are then turned into a sentence representation by a pooling mechanism, which can either be a simple mean, or a special pooler module. On to Model2Vec: the project first started as a kind of cache for sentence transformers. Because a transformer vocabulary typically only has about 32k tokens, a word likeastoundingly gets chopped up into four unique tokens: 'as', '##tou', '##nding', '##ly', which means that we re-compute the attention between those four tokens each time this word occurs. But the meaning of this word might not be ambiguous at all!
However, as we started implementing this, we noticed that you actually do not need to cache any words at all, and you can just use the output representations of individual tokens to get good sentence representations. And this is exactly what the basic mode of operation of Model2Vec is: for each of the 32k input tokens in a sentence transformer vocabulary, we do a forward pass, and then store the resulting embedding. For a new sentence, we then just take the mean of the token embeddings we computed.
Note that the output token representations of a model2vec model are uncontextualized. Unlike with normal transformer models, there is no way for the model to give different meanings to the same token in different contexts. While this might seem like a huge downside, we think that the actual context provides models with enough disambiguation potential.
In addition to this trick, we show that two additional tricks are necessary to get optimal performance.
PCA
We reduce the dimensionality of the resulting token space by using Principal Component Analysis (PCA). Normally, using PCA is associated with a loss in performance, because you throw away information. However, in our case, reducing the dimensionality actually increased performance significantly. We think this is because PCA also normalizes the resulting space, in the sense of removing biases in the original vector space, thereby making it easier to learn from the vectors.Zipf
As we take a simple mean over tokens in the space, it is important that the vectors are weighted correctly. Normally, a sentence transformer would be there to correctly weight all the tokens for us given the context, but we don’t have that luxury any more. Intuitively, we would like to use something like Inverse Document Frequency (IDF) to down-weight very frequent or uninteresting words. But we don’t have access to a corpus over which to compute document frequencies. To overcome this, we opt to use a well-known principle from language sciences, which is that, given a frequency ranked list, the frequency of the items in that list follow a power law distribution. This is called Zipf’s law. So, if we take the assumption that a vocabulary is ranked by frequency, we can accurately down-weight really frequent items without needing to have access to actual frequencies. As tokenizer vocabularies are sorted by frequency, we already have access to a ranked list, so this optimization can be applied without any additional work. |
|---|
| Visualization of the effects of applying PCA and Zipf weighting on the embeddings. |
Usage
The Model2Vec library has two broad modes of usage: distillation and inference. In distillation mode, you can distill your own model using any Sentence Transformer (and optionally your own vocabulary). In inference mode, you can use the distilled model (or use one of our pre-distilled models) to generate embeddings for your text data at extremely high speed. There are three ways to distill a model:- Output: behaves much like a real sentence transformer, i.e., it uses a subword tokenizer and simply encodes all wordpieces in its vocabulary. This is really quick to create (30 seconds on a CPU), very small (30 MB in float32), but might be less performant on some tasks.
- Vocab (word): In this mode, you can pass your own vocabulary to create representations. This allows you to create good representations for whatever in-domain data you have, and is a drop-in replacement for GloVe or word2vec.
- Vocab (subword): In this mode, you can pass your own vocabulary, but it also uses the subword vocabulary to create representations. This allows you to create good representations for whatever in-domain data you have.
How to use Model2Vec
Installation
Model2Vec can be installed using pip:Usage
Inference
The easiest way to get started with Model2Vec is to download one of our flagship models from our HuggingFace hub. These models are pre-trained and ready to use. The following code snippet shows how to load a model and make embeddings:StaticEmbedding class using from_model2vec. To directly distill in Sentence Transformers, the StaticEmbedding class can be initialized using from_distillation:
Results
We evaluated Model2Vec on a large number of tasks and datasets. Model2Vec is evaluated on MTEB, as well as two additional tasks: PEARL (a phrase representation task) and WordSim (a collection of word similarity tasks). The results are shown in the table below.| Model | Avg (All) | Avg (MTEB) | Class | Clust | PairClass | Rank | Ret | STS | Sum | Pearl | WordSim |
|---|---|---|---|---|---|---|---|---|---|---|---|
| all-MiniLM-L6-v2 | 56.08 | 56.09 | 62.62 | 41.94 | 82.37 | 58.04 | 41.95 | 78.90 | 30.81 | 60.83 | 49.91 |
| M2V_base_glove_subword | 49.06 | 46.69 | 61.27 | 30.03 | 74.71 | 49.15 | 27.16 | 69.09 | 30.08 | 56.82 | 57.99 |
| M2V_base_glove | 48.58 | 47.60 | 61.35 | 30.52 | 75.34 | 48.50 | 29.26 | 70.31 | 31.50 | 50.28 | 54.29 |
| M2V_base_output | 46.79 | 45.34 | 61.25 | 25.58 | 74.90 | 47.63 | 26.14 | 68.58 | 29.20 | 54.02 | 49.18 |
| GloVe_300d | 42.84 | 42.36 | 57.31 | 27.66 | 72.48 | 43.30 | 22.78 | 61.90 | 28.81 | 45.65 | 43.05 |
| BPEmb_50k_300d | 39.34 | 37.78 | 55.76 | 23.35 | 57.86 | 43.21 | 17.50 | 55.10 | 29.74 | 47.56 | 41.28 |
| Model | Average | SST2 | IMDB | TREC | AG News |
|---|---|---|---|---|---|
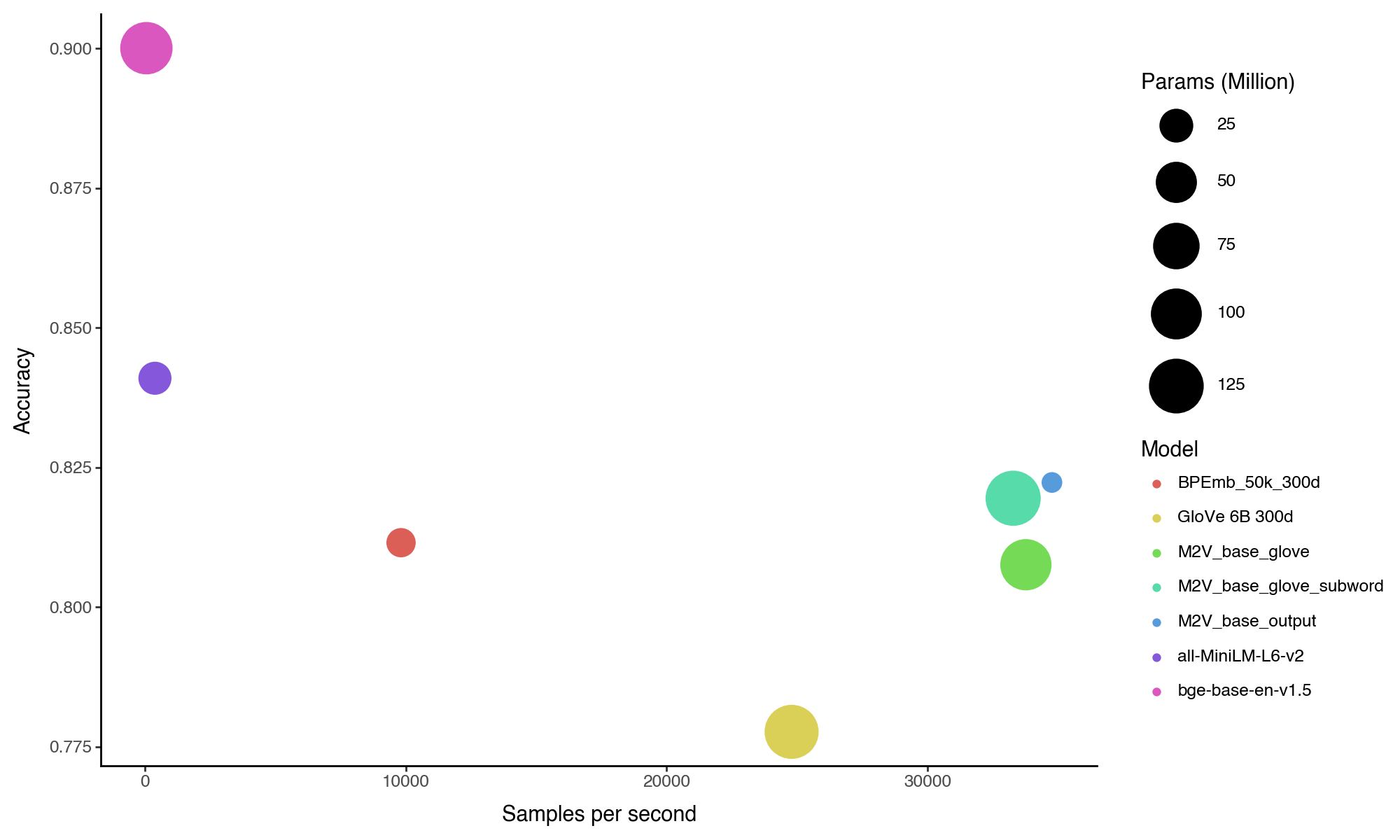
| bge-base-en-v1.5 | 90.00 | 91.54 | 91.88 | 85.16 | 91.45 |
| all-MiniLM-L6-v2 | 84.10 | 83.95 | 81.36 | 81.31 | 89.77 |
| M2V_base_output | 82.23 | 80.92 | 84.56 | 75.27 | 88.17 |
| M2V_base_glove_subword | 81.95 | 82.84 | 85.96 | 70.51 | 88.49 |
| BPEmb_50k_300d | 81.15 | 80.42 | 84.04 | 71.25 | 88.92 |
| M2V_base_glove | 80.76 | 83.07 | 85.24 | 66.12 | 88.61 |
| GloVe_300d | 77.77 | 81.68 | 84.00 | 55.67 | 89.71 |
 |
|---|
| The average accuracy over all classification datasets plotted against sentence per second. The circle size indicates model size. |
Ablations
To better understand the factors contributing to the performance of Model2Vec, we conducted a comprehensive set of ablation studies, covering various aspects of the model’s architecture and preprocessing methods. In these studies, we examined the impact of key elements such as PCA, Zipf weighting, and the use of Sentence Transformers versus regular transformer models. We also compared the performance of input embeddings versus output embeddings, since it would seem plausible that these should also work well. The results are shown in the table below.| Model | Avg (All) | Avg (MTEB) | Class | Clust | PairClass | Rank | Ret | STS | Sum | Pearl | WordSim |
|---|---|---|---|---|---|---|---|---|---|---|---|
| M2V_base_output | 46.79 | 45.34 | 61.25 | 25.58 | 74.9 | 47.63 | 26.14 | 68.58 | 29.2 | 54.02 | 49.18 |
| M2V_base_output_nopca | 44.04 | 42.31 | 61.42 | 20.15 | 68.21 | 44.67 | 25.25 | 61.87 | 29.85 | 51.02 | 48.96 |
| M2V_base_output_nozipf | 43.61 | 41.52 | 60.44 | 21.62 | 72.15 | 45.57 | 20.35 | 62.71 | 30.66 | 52.28 | 49.17 |
| M2V_base_input_nozipf_nopca | 40.97 | 39.55 | 54.16 | 18.62 | 68.3 | 43.65 | 23.63 | 59.38 | 32.04 | 50.19 | 40.52 |
| M2V_base_output_nozipf_nopca | 40.8 | 38.44 | 59.78 | 19.31 | 62.39 | 42.26 | 19.01 | 55.16 | 30 | 49.09 | 48.97 |
| M2V_base_input | 40.74 | 39.93 | 60.35 | 22.66 | 59.63 | 43.02 | 25.47 | 50.05 | 29.35 | 50.61 | 34.47 |
| M2V_bert_output_nozipf_nopca | 35.54 | 34.82 | 55.69 | 15.42 | 58.68 | 39.87 | 12.92 | 55.24 | 30.15 | 46.9 | 26.72 |
- Non-Sentence Transformers do not work well. This can be seen by comparing
M2V_bert_output_nozipf_nopca(which uses BERT, a non-Sentence Transformer) andM2V_base_output_nozipf_nopca(which uses BGE-base, a Sentence Transformer). Using a Sentence Transformer gives a ~5.2% increase in performance. - PCA is crucial for performance. This can be seen by comparing
M2V_base_output_nozipf_nopcaandM2V_base_output_nozipfwhich gives a ~2.8% increase in performance. Furthermore, PCA improves performance on all tasks. - Zipf weighting is crucial for performance. This can be seen by comparing
M2V_base_output_nozipf_nopcaandM2V_base_output_nopcawhich gives a ~3.1% increase in performance. - Output embeddings outperform input embeddings. This can be seen by comparing
M2V_base_inputandM2V_base_outputwhich gives a ~6.1% increase in performance. Note that input embeddings do work well for some tasks. We hypothesize that this is because input embeddings are inherently normalized.