Benchmarks
We benchmark quality and speed across all methods on ~1,250 queries over 63 repositories in 19 languages.
Main Results
| Method | NDCG@10 | Index time | Query p50 |
|---|---|---|---|
| CodeRankEmbed Hybrid | 0.862 | 57 s | 16 ms |
| semble | 0.854 | 263 ms | 1.5 ms |
| CodeRankEmbed | 0.765 | 57 s | 16 ms |
| ColGREP | 0.693 | 5.8 s | 124 ms |
| BM25 | 0.673 | 263 ms | 0.02 ms |
| grepai | 0.561 | 35 s | 48 ms |
| probe | 0.387 | - | 207 ms |
| ripgrep | 0.126 | - | 12 ms |
Semble achieves 99% of the retrieval quality of the 137M-parameter CodeRankEmbed Hybrid, while indexing 218× faster and answering queries 11× faster, entirely on CPU.
The charts below plot latency against NDCG@10. Marker size reflects model parameter count.
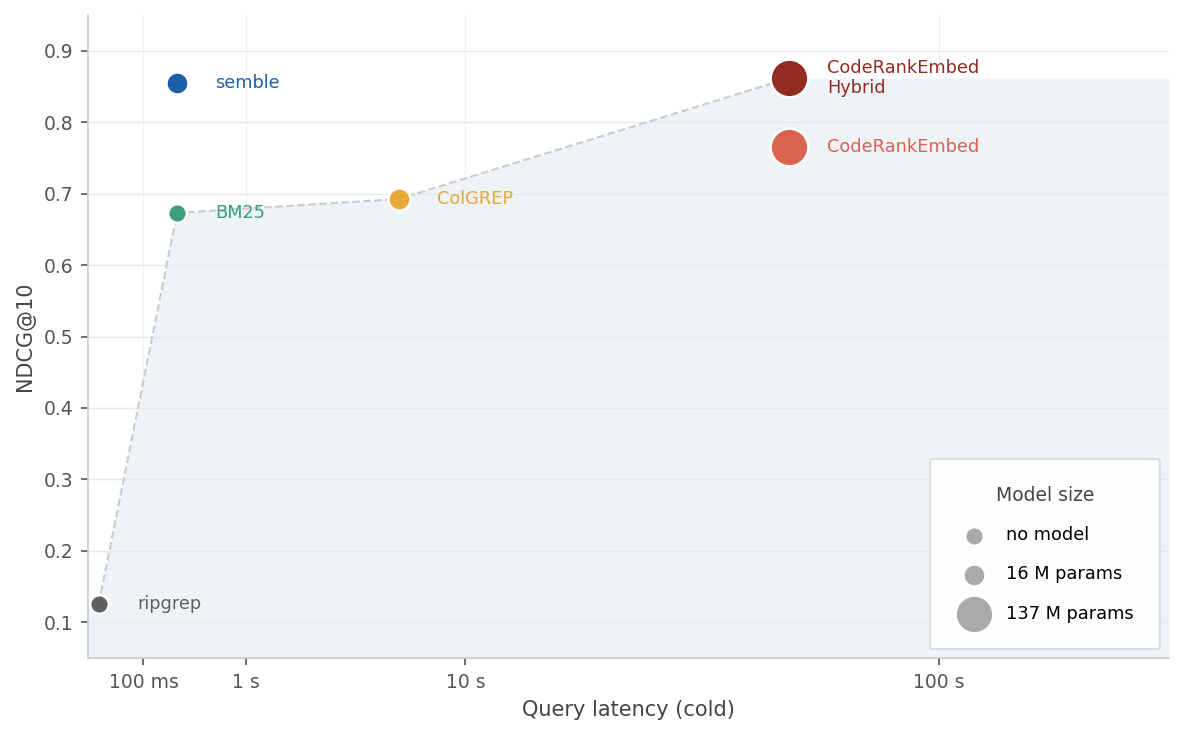 Time to first result (index + query) vs NDCG@10
Time to first result (index + query) vs NDCG@10
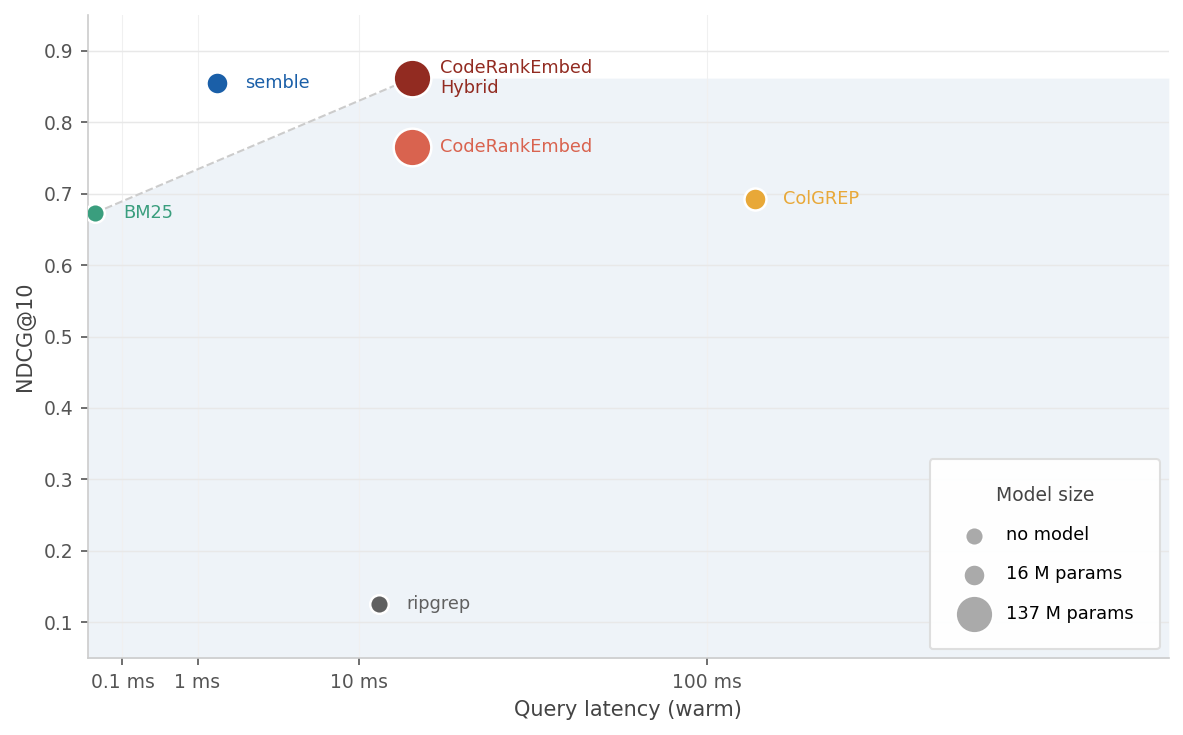 Query latency on a warm index vs NDCG@10
Query latency on a warm index vs NDCG@10
Token Efficiency
Coding agents (Claude Code, OpenCode, etc.) typically find code by running grep on keywords and reading the matched files. We model that workflow and compare it against semble’s chunk retrieval across our full benchmark of 1,251 queries.
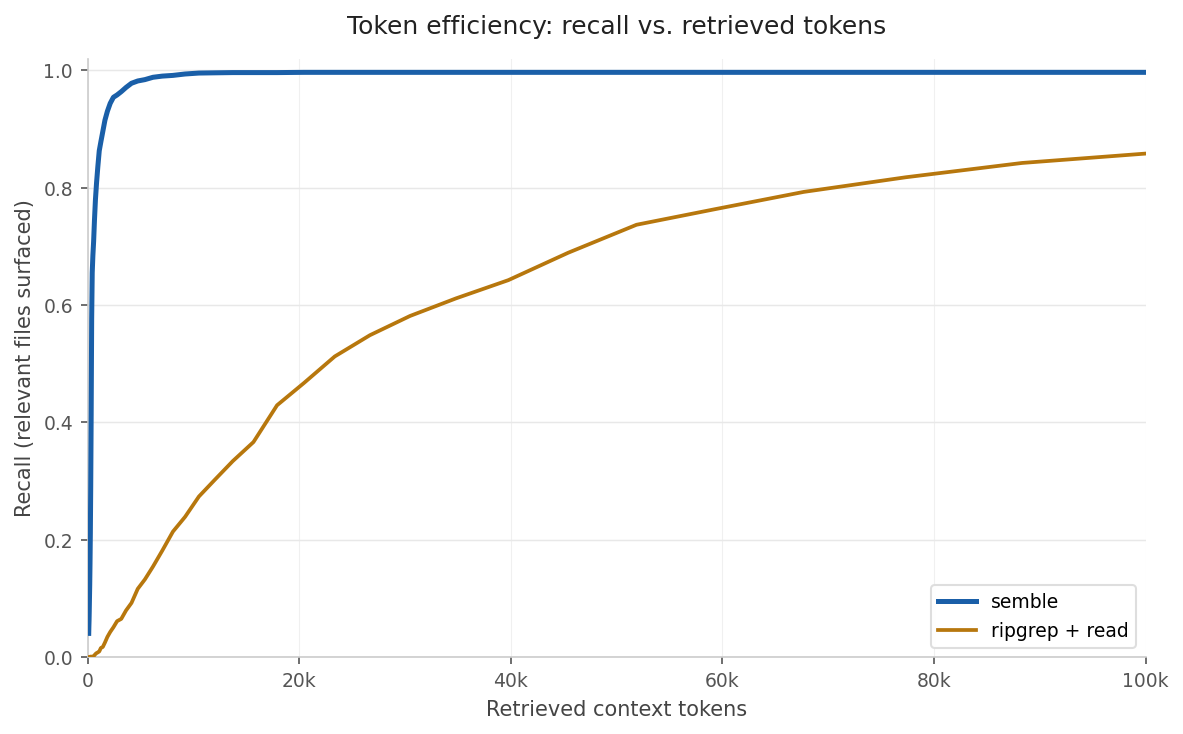
Expected tokens per query
For each query: tokens consumed at first relevant hit, or 32k if the method never finds anything. Averaged across all 1,251 queries.
| Method | Expected tokens | Savings |
|---|---|---|
| ripgrep + read file | 45,692 | baseline |
| semble | 566 | 98% fewer |
Recall at fixed token budgets
A relevant file is “covered” once any retrieved unit comes from it.
| Method | 500 | 1k | 2k | 4k | 8k | 16k | 32k |
|---|---|---|---|---|---|---|---|
| semble | 0.685 | 0.849 | 0.938 | 0.976 | 0.991 | 0.996 | 0.996 |
| ripgrep + read file | 0.001 | 0.008 | 0.037 | 0.088 | 0.212 | 0.379 | 0.583 |
Methodology
Semble returns the top-50 ranked chunks. ripgrep+read splits the query into keywords (dropping stopwords and short words), runs rg --fixed-strings --ignore-case for each keyword, then reads matched files in full ranked by how many distinct keywords they contain. Both methods search the same set of file types and ignored directories. Tokens are counted with cl100k_base via tiktoken. A relevant file is “covered” once any retrieved unit overlaps its annotated span.
By Language
NDCG@10 per language. Best score per row is bolded.
| Language | semble | CRE Hybrid | CRE | ColGREP | grepai | probe | ripgrep |
|---|---|---|---|---|---|---|---|
| scala | 0.909 | 0.922 | 0.845 | 0.765 | 0.330 | 0.392 | 0.180 |
| cpp | 0.915 | 0.913 | 0.846 | 0.626 | 0.731 | 0.375 | 0.126 |
| ruby | 0.909 | 0.909 | 0.769 | 0.708 | 0.643 | 0.382 | 0.230 |
| elixir | 0.894 | 0.905 | 0.869 | 0.808 | 0.669 | 0.412 | 0.134 |
| javascript | 0.917 | 0.903 | 0.920 | 0.823 | 0.675 | 0.588 | 0.176 |
| zig | 0.913 | 0.901 | 0.807 | 0.474 | 0.755 | 0.369 | 0.000 |
| csharp | 0.885 | 0.889 | 0.743 | 0.614 | 0.277 | 0.392 | 0.117 |
| go | 0.895 | 0.884 | 0.676 | 0.785 | 0.722 | 0.410 | 0.133 |
| python | 0.867 | 0.880 | 0.794 | 0.777 | 0.634 | 0.488 | 0.202 |
| php | 0.858 | 0.874 | 0.758 | 0.663 | 0.402 | 0.340 | 0.123 |
| swift | 0.860 | 0.873 | 0.721 | 0.710 | 0.429 | 0.280 | 0.160 |
| bash | 0.825 | 0.852 | 0.892 | 0.706 | 0.723 | 0.226 | 0.000 |
| lua | 0.823 | 0.847 | 0.803 | 0.798 | 0.699 | 0.336 | 0.000 |
| java | 0.849 | 0.841 | 0.706 | 0.641 | 0.386 | 0.536 | 0.198 |
| kotlin | 0.821 | 0.830 | 0.670 | 0.637 | 0.478 | 0.335 | 0.166 |
| rust | 0.856 | 0.827 | 0.627 | 0.662 | 0.519 | 0.242 | 0.162 |
| c | 0.741 | 0.806 | 0.706 | 0.676 | 0.555 | 0.384 | 0.000 |
| haskell | 0.765 | 0.771 | 0.776 | 0.683 | 0.483 | 0.313 | 0.000 |
| typescript | 0.706 | 0.708 | 0.545 | 0.430 | 0.394 | 0.354 | 0.128 |
| overall | 0.854 | 0.862 | 0.765 | 0.693 | 0.561 | 0.387 | 0.126 |
Ablations
raw returns retrieval scores directly; + ranking feeds them through semble’s hybrid reranker.
| Retrieval | Raw | + ranking |
|---|---|---|
| BM25 | 0.675 | 0.834 |
| potion-code-16M | 0.650 | 0.821 |
| BM25 + potion-code-16M | - | 0.854 |
By query category:
| Mode | Architecture | Semantic | Symbol |
|---|---|---|---|
| BM25 raw | 0.628 | 0.676 | 0.719 |
| potion-code-16M raw | 0.626 | 0.666 | 0.629 |
| semble BM25 (+ ranking) | 0.770 | 0.819 | 0.957 |
| semble potion-code-16M (+ ranking) | 0.757 | 0.808 | 0.943 |
| semble hybrid | 0.802 | 0.846 | 0.958 |
Dataset
~1,250 queries over 63 repositories in 19 languages, grouped into three categories:
| Category | Queries | What it tests |
|---|---|---|
| semantic | 711 | Code that implements a specific behavior or concept |
| architecture | 343 | Design decisions, module boundaries, structural patterns |
| symbol | 204 | Named entity lookup (function, class, type, variable) |
Languages covered: bash, C, C++, C#, Elixir, Go, Haskell, Java, JavaScript, Kotlin, Lua, PHP, Python, Ruby, Rust, Scala, Swift, TypeScript, Zig.
Methods
- ripgrep: fast regex search, included as a raw keyword-match baseline.
- probe: BM25 keyword ranking backed by tree-sitter parse trees. No persistent index; scans on the fly.
- ColGREP: late-interaction code retrieval with the LateOn-Code-edge model.
- grepai: semantic search using nomic-embed-text (137M params) via a local Ollama daemon.
- CodeRankEmbed: 137M-param transformer embedding model. CRE Hybrid fuses its dense scores with BM25.
- semble: potion-code-16M static embeddings + BM25 + the semble reranking stack.